Lösung
Machine Learning und GPU
Deep Learning
Welche grundlegenden Rechenoperationen sind für ML Anwendungen wichtig?
Die Grundlagen des maschinellen Lernens (ML) und Deep Learning basieren auf einer Vielzahl mathematischer und statistischer Operationen, die auf Daten angewendet werden, um Muster zu erkennen, Vorhersagen zu treffen und Entscheidungen zu automatisieren. Die Rechenoperationen, die für ML-Anwendungen besonders wichtig sind, lassen sich in verschiedene Kategorien einteilen, von einfachen arithmetischen Operationen bis hin zu komplexeren mathematischen Verfahren. Die Rolle der GPUs (Graphics Processing Units) wird ebenfalls diskutiert, da sie für die Beschleunigung dieser Rechenoperationen unerlässlich sind.
Arithmetische Operationen
-
Addition und Subtraktion werden häufig für Datenanpassungen und Fehlerkorrekturen eingesetzt. Beispielsweise können sie verwendet werden, um den Mittelwert von Daten für Normalisierungszwecke zu berechnen oder um die Differenz zwischen den prognostizierten und tatsächlichen Werten (den Fehler) in Lernalgorithmen zu bestimmen.
-
Multiplikation und Division sind grundlegend für die Skalierung und Normalisierung von Daten, was hilft, die numerische Stabilität in Algorithmen zu verbessern und die Leistung von ML-Modellen zu optimieren.
Matrixoperationen
- Matrixmultiplikation spielt eine zentrale Rolle in vielen ML-Algorithmen, insbesondere in neuronalen Netzwerken. Neuronale Netzwerke bestehen aus Schichten von Neuronen, deren Verbindungen durch Gewichtsmatrizen dargestellt werden. Die Matrixmultiplikation wird verwendet, um die Eingaben durch diese Netzwerkschichten zu propagieren.
Optimierung
- Gradientenabstieg ist eine Optimierungsmethode, die Differentialrechnung nutzt, um das Minimum einer Verlustfunktion zu finden. Durch Berechnung des Gradienten der Funktion in Bezug auf ihre Parameter können ML-Modelle trainiert werden, indem sie die Parameter schrittweise in die Richtung des steilsten Abstiegs anpassen.
Faltungsoperationen
- Faltungsoperationen sind speziell in der Bild- und Signalverarbeitung von Bedeutung und bilden das Rückgrat von Convolutional Neural Networks (CNNs). Sie ermöglichen es, Merkmale aus Daten effizient zu extrahieren, indem sie Filter oder Kerne über die Eingabedaten schieben und dabei Muster wie Kanten, Texturen oder andere relevante Merkmale identifizieren.
Rolle der GPU in ML und Deep Learning
GPUs sind aufgrund ihrer Fähigkeit, parallele Verarbeitung durchzuführen, besonders gut für die Beschleunigung der oben genannten Rechenoperationen geeignet. Während CPUs (Central Processing Units) für allgemeine Rechenaufgaben konzipiert sind und eine geringere Anzahl von Kernen mit höherer Taktrate besitzen, verfügen GPUs über eine viel grössere Anzahl von Recheneinheiten, die speziell für die gleichzeitige Ausführung vieler Operationen optimiert sind. Dies macht sie ideal für die massiven parallelen Rechenanforderungen von ML und Deep Learning, insbesondere für Aufgaben wie Matrixmultiplikationen, Faltungsoperationen und die Durchführung von Gradientenabstiegsberechnungen.
Durch den Einsatz von GPUs können ML-Modelle und Deep Learning-Algorithmen erheblich schneller trainiert und ausgeführt werden, was die Entwicklung und den Einsatz komplexer Modelle ermöglicht, die ohne diese Rechenleistung nicht praktikabel wären.
Wieso können ML Anwendungen so stark parallelisiert werden?
ML-Anwendungen können stark parallelisiert werden, hauptsächlich wegen zwei Schlüsselfaktoren:
-
Unabhängige Datenverarbeitung: Viele ML-Algorithmen verarbeiten einzelne Datenpunkte oder Datenbatches unabhängig voneinander, was bedeutet, dass diese Verarbeitungsschritte gleichzeitig auf verschiedenen Prozessoren oder Rechenkernen durchgeführt werden können.
-
Matrix- und Vektoroperationen: Diese sind grundlegende Bestandteile von ML-Algorithmen, insbesondere in neuronalen Netzwerken, und lassen sich gut aufteilen in kleinere, parallele Aufgaben, die simultan ausgeführt werden können. GPUs sind speziell für solche Operationen optimiert, was die Parallelverarbeitung weiter erleichtert.
Diese Eigenschaften ermöglichen es, die Berechnungen über viele Prozessorkerne zu verteilen, wodurch ML-Modelle schneller trainiert und angewendet werden können.
How GPU Computing Works | GTC 2021
Wie Unterscheiden sich GPUs von CPUs?
GPUs (Graphics Processing Units) und CPUs (Central Processing Units) unterscheiden sich hauptsächlich in ihrer Architektur und Verarbeitungsfähigkeit. CPUs sind mit wenigen, aber leistungsstarken Kernen ausgestattet, die auf effiziente sequenzielle Verarbeitung ausgelegt sind, was sie ideal für eine Vielzahl von allgemeinen Rechenaufgaben macht. GPUs besitzen hingegen tausende von kleineren Kernen, die für die parallele Ausführung von Aufgaben konzipiert sind, was sie besonders geeignet für spezialisierte Anwendungen macht, die eine hohe Rechenleistung erfordern, wie Grafikrendering, wissenschaftliche Simulationen und maschinelles Lernen. Diese strukturelle Differenz führt dazu, dass GPUs in der Lage sind, viele Berechnungen gleichzeitig durchzuführen, während CPUs sich auf die schnelle Ausführung einer kleineren Anzahl von Prozessen konzentrieren.
Wie ermöglichen GPUs die hohe parallele Ausführung von Berechnungen?
Auf dem Bild ist eine Grafikkarte zu sehen, die viele kleine Recheneinheiten hat, die alle gleichzeitig arbeiten können. Jede dieser Einheiten kann einen kleinen Teil einer größeren Aufgabe übernehmen. Weil es so viele davon gibt, können sie alle zusammen viele Teile auf einmal bearbeiten. So können Grafikkarten sehr schnell viele Berechnungen durchführen, was sie super für Dinge macht, die viel Grafikleistung brauchen, wie Videospiele oder wissenschaftliche Programme.
Cloud Computing
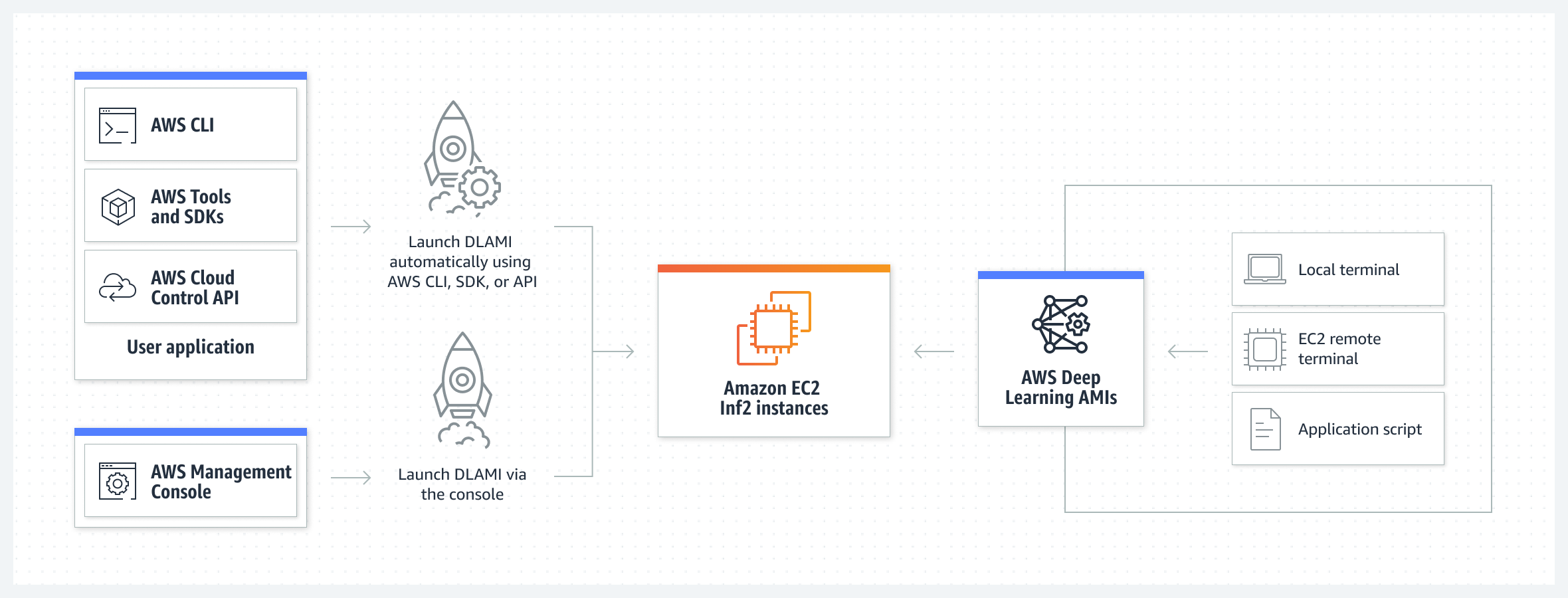
Wie ist der AWS Inferentia2 aufgebaut?
Der AWS Inferentia2 ist ein Beschleuniger für Deep-Learning-Inferenzen, der mit zwölf Geräten ausgestattet ist, die jeweils zwei NeuronCore-v2 Kerne enthalten. Die hohe Rechenleistung dieser Kerne wird durch einen hohen Bandbreitenspeicher mit signifikanter Bandbreite von 32 GiB unterstützt. Inferentia2 bietet erweiterte Funktionen für die Handhabung dynamischer Formen und Kontrollflüsse und unterstützt durch NeuronLink-v2 für optimierte Geräteverbindungen, um Datentransfers mit hoher Geschwindigkeit und Effizienz durchzuführen. Weitere Informationen finden Sie in der AWS Neuron Dokumentation.
Für welche Rechenoperationen ist der AWS Inferentia2 optimiert?
Der AWS Inferentia2 wurde entwickelt, um eine Vielzahl von Rechenoperationen wie INT8, FP16, BF16, cFP8, TF32 und FP32 zu unterstützen. Er bietet hohe Leistung für Deep-Learning-Inferenz-Aufgaben und wird durch spezialisierte Hardwarekomponenten wie NeuronCore-v2 Kerne, High-Bandwidth-Memory und NeuronLink-v2 unterstützt, um effiziente Geräteverbindungen zu gewährleisten. Inferentia2 kann aufgrund dieser Verbesserungen zahlreiche Machine-Learning-Modelle und Anwendungen effektiv unterstützen.
Beispiel:
Wie unterscheiden sich die KI-Beschleuniger-Instanzen von herkömmlichen CPU-Instanzen?
KI-Beschleuniger-Instanzen sind speziell für KI- und ML-Aufgaben optimiert und bieten im Gegensatz zu herkömmlichen CPU-Instanzen deutlich höhere Rechenleistung bei solchen Anwendungen. Sie nutzen spezielle Hardware wie GPUs oder ASICs, die für parallele Datenverarbeitung und spezifische Rechenoperationen entwickelt wurden, die in KI-Modellen häufig vorkommen. Dies führt zu schnelleren Verarbeitungszeiten und effizienterem Ressourceneinsatz bei KI-Berechnungen, aber nicht so leistungsfähig bei spezialisierten KI-Aufgaben im Vergleich zu CPU-Instanzen, die für eine breitere Palette von Anwendungen konzipiert sind.
Wie sind die Preise für KI-Beschleuniger Instanzen?
AWS bietet eine Vielzahl von KI-Beschleunigerinstanzen für Deep-Learning-Inferenzen an. Die Inf2-Instanzen sind sehr leistungsfähig und kostengünstig. Aufgrund ihrer äußerst schnellen internen Verbindungen können sie verteilte Inferenzen über mehrere Beschleuniger hinweg durchführen und Modelle mit hunderten Milliarden Parametern ausführen. Inf2-Instanzen sind im Vergleich zu vergleichbaren EC2-Instanzen bis zu vierzig Prozent kosteneffizienter und liefern einen bis zu vierfach höheren Durchsatz und eine bis zu zehnfach niedrigere Latenz.
Inf2-Instanzen können mit der Integration in das AWS Neuron SDK gängige maschinelle Lernframeworks und Bibliotheken unterstützen, was optimale Ergebnisse für Modelle aus bekannten Quellen wie Hugging Face gewährleistet. Sie bieten herausragende Leistungen aufgrund ihrer beeindruckenden Rechenkapazität von bis zu 2,3 Petaflops, bis zu 384 GB Hochbandbreitenspeicher für Beschleuniger und NeuronLink-Verbindungen, die schnelle Interaktionen zwischen den Beschleunigern ermöglichen.
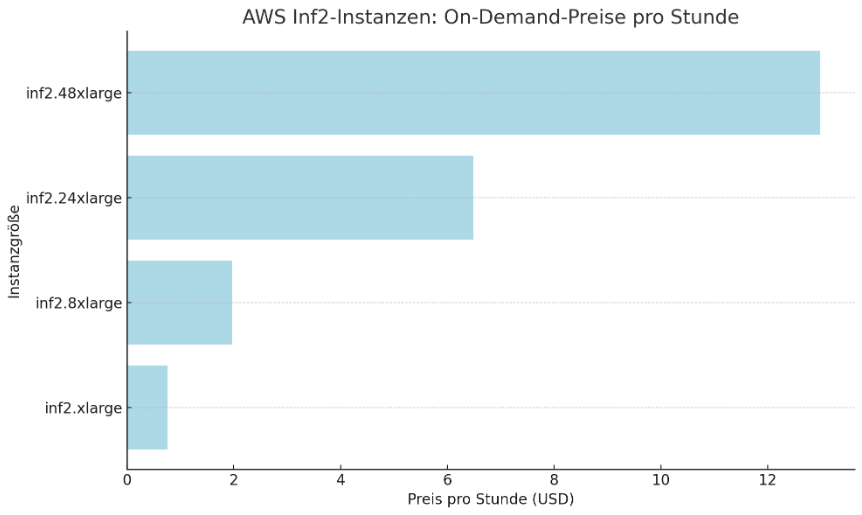
Beispielhafte Preise für Inf2-Instanzen in der AWS-Region US East (Nord-Virginia) reichen von 0,76 USD pro Stunde für eine inf2.xlarge-Instanz bis zu 12,98 USD pro Stunde für eine inf2.48xlarge-Instanz, je nach Konfiguration. AWS bietet auch die Möglichkeit, Geld zu sparen, indem Sie 1- oder 3-jährige Reservierungen abschließen. Kundenbewertungen zeigen, dass der Einsatz von Inf1- und Inf2-Instanzen im Vergleich zu herkömmlichen GPU-basierten Lösungen verbesserte Leistung pro Inferenz sowie erhebliche Kosten- und Latenzzeiten verringert.
Preise
| Instance-Größe | Inferentia2-Beschleuniger | Beschleuniger Arbeitsspeicher (GB) |
vCPU | Arbeitsspeicher (GiB) |
Lokale Speicherung |
Inter-Beschleuniger Interconnect |
Netzwerk Bandbreite (Gbit/s) |
EBS Bandbreite (Gbit/s) |
On-Demand-Preise | Reservierte Instance für 1 Jahr | Reservierte Instance für 3 Jahre |
| inf2.xlarge | 1 | 32 | 4 | 16 | Nur EBS | – | Bis zu 15 | Bis zu 10 | 0,76 USD | 0,45 USD | 0,30 USD |
| inf2.8xlarge | 1 | 32 | 32 | 128 | Nur EBS | – | Bis zu 25 | 10 | 1,97 USD | 1,81 USD | 0,79 USD |
| inf2.24xlarge | 6 | 192 | 96 | 384 | Nur EBS | Ja | 50 | 30 | 6,49 USD | 3,89 USD | 2,60 USD |
| inf2.48xlarge | 12 | 384 | 192 | 768 | Nur EBS | Ja | 100 | 60 | 12,98 USD | 7,79 USD | 5,19 USD |
No Comments